Думай повільно... Вирішуй швидко (Д. Канеман)
Сторінка: Перша < 16 17 18 19 20 > Остання цілком
8
Як судження виносяться
Переліком запитань, на які ви можете відповісти, немає меж, незалежно від того, запитує вас співрозмовник, або ви задаєте їх самі собі. Немає межі і числа ознак, які ви можете оцінити. Ви здатні порахувати кількість заголовних букв на цій сторінці, порівняти висоту вікон у вашому будинку і будинку через вулицю і оцінити починання якого-небудь політичного діяча по шкалі від «відмінно» до «провально». Питання адресуються Системі 2, яка направить увагу на пошук відповіді в пам'яті. Система 2 питання може отримувати, а може генерувати, але перенаправлення уваги і пошук відповіді в пам'яті відбуваються в будь-якому випадку. Система 1 працює по-іншому. Вона постійно відстежує, що відбувається всередині і зовні розуму, і генерує оцінки різних аспектів ситуації без конкретного наміри і майже або зовсім без зусиль. Ці базові оцінки відіграють важливу роль у інтуїтивні судження, оскільки їх з легкістю підставляють замість більш складних відповідей - це і є основна ідея методу евристики і спотворень. Дві інші риси Системи 1 також підтримують заміну одного судження на інше. Одна з них - здатність переносити значення між вимірами. Ви робите це, відповідаючи на легкий для більшості питання: «Якщо б Сем був такий же високий, як він розумний, якого росту він був?» І, нарешті, є «уявний постріл дробом» (mental shotgun): намір Системи 2 відповісти на конкретне питання або оцінити певну властивість ситуації автоматично запускає інші обчислення, в тому числі і базові оцінки.
Базові оцінки
В ході еволюції Система 1 виробила здатність забезпечувати постійну оцінку основних завдань, які організм повинен вирішувати для виживання: як йдуть справи? не виникла загроза? не з'явилася гарна можливість? все нормально? наблизитися або триматися подалі? Напевно, ці питання не настільки важливі для міського жителя, як для газелі в савані, але ми успадкували нейронні механізми, безперервно оцінюють рівень загрози, які не можна відключити. Ситуації постійно визначаються як погані чи хороші, що вимагають втечі або дозволяють наближення. Для людини гарний настрій і когнітивна легкість - еквіваленти оцінки середовища як безпечної та знайомої.
Конкретним прикладом базової оцінки служить здатність з одного погляду відрізнити друга від ворога. Подібна спеціалізована можливість впливає на шанси виживання організму в небезпечному світі і розвинулася в ході еволюції. Алекс Тодоров, мій колега по Принстону, вивчав біологічні коріння швидкої оцінки безпеки при взаємодії з сторонніми. Він показав, що у нас є здатність з одного погляду на обличчя незнайомця оцінювати два основних і потенційно важливих ознаки: рівень його домінантності (і, відповідно, ступінь небезпеку) і наскільки він гідний довіри, тобто виявляться його наміри дружніми або ворожими. Форма обличчя, наприклад «сильна» квадратна щелепа, дозволяє певною мірою оцінити домінантність. Вираз обличчя (посмішка або похмурий погляд) дає підказки щодо намірів. Поєднання квадратної щелепи з опущеними куточками рота може передвіщати біди. Точність такої оцінки далеко не ідеальна: круглі підборіддя не дуже надійно відображають лагідність, а посмішки можна (до певної міри) зімітувати. І все-таки навіть недосконала здатність оцінювати сторонніх дає перевагу при виживанні.
Цей древній механізм у сучасному світі отримав нове використання: він до певної міри впливає на те, як люди голосують. Тодоров показував своїм студентам фотографії чоловіків, деякі лише на одну десяту секунди, і просив їх оцінити особи за різними ознаками, включаючи привабливість і компетентність. В оцінках випробовуваних не виявилося значного розкиду. Тодоров показував не набір випадкових фотографій, а добірку зображень кандидатів у передвиборних кампаніях. Потім дослідник порівняв результати виборів з рейтингом компетентності, складеним принстонскими студентами після короткого перегляду фотографій і поза політичного контексту. Приблизно в 70 % випадків на виборах на пост сенатора, конгресмена і губернатора переміг той кандидат, чиє зображення в експерименті отримала більш високий рейтинг компетентності. Цей вражаючий результат швидко підтвердився під час загальної виборчої кампанії у Фінляндії, на виборах у муніципальні ради в Англії і у різних виборчих кампаніях в Австралії, Німеччині та Мексиці. Для мене повною несподіванкою стало те, що рейтинг компетентності в дослідженні Тодорова прогнозував результати голосування краще, ніж рейтинг привабливості.
Тодоров виявив, що люди судять про компетентності, поєднуючи два виміри: силу і надійність. На осіб, випромінювальних компетентність, сильний підборіддя поєднується з легкої впевненою посмішкою. Немає жодних свідчень, що ці риси обличчя дійсно передбачають, наскільки добре політики впораються зі своїми обов'язками. Але вивчення реакції мозку на виграють і програють кандидатів демонструє, що ми біологічно схильні відкидати тих, у кого немає шанованих нами ознак. У цьому дослідженні переможені викликали більш сильну негативну емоційну реакцію. Це - приклад евристики судження, про яку я буду говорити далі. Виборці намагаються скласти враження про те, наскільки буде хороший кандидат на своєму посту, і схиляються до більш простої оцінки, яка виноситься швидко, автоматично і доступна в момент, коли Система 2 приймає рішення.
Розвиваючи основоположні дослідження Тодорова, політологи визначили категорію виборців, для яких автоматичні переваги Системи 1, імовірніше всього, відіграють значну роль. Вони виявили їх серед політично неграмотних виборців, які багато дивляться телевізор. Як і очікувалося, зовнішність, створює враження компетентності, впливає на недостатньо інформованих любителів телепередач втричі сильніше, ніж на інших. Зрозуміло, відносна важливість Системи 1 визначення переваг вибору при голосуванні для всіх різна. Ми зустрінемо і інші приклади таких індивідуальних відмінностей.
Система 1, звичайно ж, розуміє мову, і це розуміння залежить від базових оцінок, які постійно генеруються в ході сприйняття подій і розуміння повідомлень. Ці оцінки включають высчитывание подібності і репрезентативності, встановлення причин і оцінку доступності асоціацій і прикладів. Це робиться навіть при відсутності конкретних завдань, хоча результати використовуються для виконання вимог, що виникають по мірі появи завдань.
Базових оцінок дуже багато, але оцінюються не всі можливі ознаки. Для прикладу погляньте на малюнок 7.
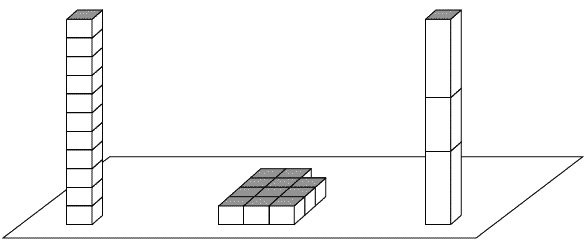
З першого погляду складається враження про багатьох особливості малюнка. Ви знаєте, що висота крайніх стовпчиків однакова і що схожість стовпчиків один з одним більше, ніж подібність між стовпчиком зліва і масивом кубиків посередині. Ви не усвідомлюєте, що кількість кубиків в стовпчику зліва таке ж, як у середній фігурі, і не знаєте, якої висоти буде стовпчик, споруджений із кубиків. Щоб підтвердити кількість, доведеться перерахувати два набори кубиків і порівняти результати, а це може зробити лише Система 2.
Набори та прототипи

В якості іншого прикладу подумайте над таким питанням: яка середня довжина ліній на малюнку 8?
Питання легкий, і Система 1 відповідає на нього без підказок. Експерименти показали, що випробуваним досить частки секунди для досить точної оцінки середньої довжини набору ліній. Більш того, точність цих оцінок не страждає, якщо мозок випробуваного в цей же час зайнятий тестом на пам'ять. Випробовувані не завжди знають, як висловити середнє значення в дюймах або сантиметрах, але дуже точно підганяють під нього довжину іншій лінії. Щоб сформувати враження про середній довжині, Система 2 не потрібна. Це автоматично і без зусиль робить Система 1, точно так само, як вона зазначає кольору ліній і факт, що вони не паралельні. Ми можемо негайно сформувати враження про кількість предметів в наборі: точно, якщо їх число дорівнює або менше чотирьох, або приблизно, якщо воно більше чотирьох.
Перейдемо до іншого питання: яка сумарна довжина ліній на малюнку 8? З ним все по-іншому, тому що Системі 1 нічого запропонувати. На нього можна відповісти, лише активувавши Систему 2, яка старанно оцінить середню довжину, порахує кількість ліній і перемножит їх.
На перший погляд те, що Система 1 не може обчислити загальну довжину декількох ліній, цілком очевидно, ви і не гадали, що можете це зробити. Це приклад важливого обмеження Системи 1. Вона являє категорії через прототип або кілька типових зразків, а тому добре справляється зі середніми значеннями, але не дуже добре - з підсумовуванням. Обсяг категорії та кількість об'єктів в ній зазвичай ігноруються в думках щодо того, що я буду називати суммоподобными змінними.
В одному з численних експериментів, проведених у зв'язку з судовим процесом після аварії танкера «Ексон Вальдес», випробовуваних запитали про ступінь їх готовності оплатити придбання мереж для покриття пролитої нафти, в який грузнуть і тонуть перелітні птахи. Трьом групам учасників запропонували оплатити порятунок відповідно двох тисяч, двадцять тисяч або двохсот тисяч птахів. Якщо порятунок птахів - економічний товар, воно повинне представляти суммоподобную змінну: порятунок двохсот тисяч птахів, здавалося б, коштує дорожче, ніж порятунок двох тисяч. Насправді кількість птахів мало вплинуло на середній розмір внеску для кожної з трьох груп: 80, 78 і 88 доларів відповідно. У всіх трьох групах учасники реагували на прототип - зображення безпорадною птиці, покритої нафтою. Як неодноразово підтверджувалося досвідченим шляхом, кількістю майже завжди нехтують подібних емоційних обставинах.
Зіставлення інтенсивності
Питання про вашому благополуччі, про популярності президента, про гідне покарання фінансових махінаторів та про перспективи якогось політика об'єднує важлива риса: вони всі звертаються до лежачого в їх основі поняття інтенсивності або кількості, що дозволяє використовувати слово «більше»: більше щасливий, більш популярний, більш суворо чи більш впливовий (про політику). Приміром, політичне майбутнє кандидата може варіюватися від малого «Її обженуть ще на внутрішньопартійних виборах» до серйозного «Коли-небудь вона стане президентом США».
Тут ми стикаємося з ще однією здатністю Системи 1. Що лежить в основі шкала інтенсивності дозволяє знаходити відповідності в самих різних областях. Якби злочину виражалися через колір, вбивство придбало б більш темний відтінок червоного, ніж крадіжка. Якщо б їх виражали через музику, масове вбивство звучало б дуже голосно, а несплата штрафів за неправильну парковку - ледь чутно. Зрозуміло, ви відчуваєте щось подібне і щодо інтенсивності покарань. У класичних експериментах одні випробовувані налаштовували гучність звуку згідно з серйозністю злочину, а інші - відповідно з серйозністю покарання. Почувши один звук для злочину і інший - для покарання, ви вважали б несправедливим, якби один з них був помітно голосніше іншого.